This paper outlines the historical development of the core structure of machine learning and summarizes the eight neural network architectures that researchers need to be familiar with.
Why do we need "machine learning"?
Machine learning is essential for tasks that are too complex for us to program directly. Some tasks are so complex that it is impossible for humans to solve all the details of the task and program them accurately. So, we provide a lot of data to the machine learning algorithm, let the algorithm solve this problem by exploring the data and finding a model that can achieve the programmer's purpose.
Let's look at two examples:
It is difficult to write a program to identify three-dimensional objects with new perspectives under lighting conditions in complex scenes. We don't know what program to write because we don't understand the mechanism by which it works in our brains. Even knowing how to do it, the programs written can be very complicated.
It is very difficult to write a program to calculate the probability of credit card fraud. Because there may not be any simple and reliable rules, we need to combine a large number of weak rules to discriminate. Deception is the transfer of the target, and the program needs to be constantly changed.
Then there is the machine learning method: we don't need to manually program each specific task, just collect a large number of samples and specify the correct output for the given input. Machine learning algorithms use these samples to generate programs that do the job. The program generated by the learning algorithm may be very different from a typical handwriting program, which may contain millions of numbers. If we do it right, this program will process the new sample just like the sample on the training set. If the data changes, the program can also be changed by training new data. You should note that a lot of calculations are currently cheaper than paying programmers to write a specific task.
For this reason, examples of the most suitable tasks for machine learning include:
Pattern recognition: objects in real scenes, facial recognition or facial expressions, spoken language.
Abnormal recognition: unusual credit card transaction sequence, abnormal mode of nuclear power plant sensor readings.
Forecast: Future stock price or currency exchange rate, what movie a person likes.
What is a neural network?Neural networks are a type of model in the machine learning literature. For example, if you take part in Coursera's machine learning course, you are likely to learn about neural networks. Neural networks are a specific set of algorithms that revolutionize the field of machine learning. They are inspired by biological neural networks, and deep neural networks have proven to work well. Neural networks are themselves general function approximations, which is why they can be applied to almost any machine learning problem from complex mapping of input to output space.
Here are three reasons to convince you to learn neural computing:
Learn how the brain works: it's very large and complex, and once it breaks, it kills the brain, so we need to use computer simulation.
Learn about parallel computing styles inspired by neurons and their adaptive connections: this style is quite different from sequence calculations.
Use brain-inspired novel learning algorithms to solve real-world problems: learning algorithms are useful even if they are not the way the brain actually works.
After completing Wu Enda's Coursera machine learning course, I became interested in neural networks and deep learning, so I looked for the best online resources to learn about this topic and found Geoffrey Hinton's machine learning neural network course. If you are doing a deep learning project or want to enter the field of deep learning / machine learning, you should take this course. Geoffrey Hinton is undoubtedly the godfather of deep learning, giving extraordinary insights in the course. In this blog post, I want to share eight neural network architectures that I think any machine learning researchers should be familiar with to promote their work.

In general, these architectures can be divided into three categories:
Feedforward neural network
This is the most common type of neural network in practical applications. The first layer is the input and the last layer is the output. If there are multiple hidden layers, we call it a "deep" neural network. They calculated a series of transformations that changed the similarity of the samples. The activity of neurons in each layer is a nonlinear function of the activity of the previous layer.
2. Cyclic network
The looping network orients loops in their connection diagrams, which means you can follow the arrows to get back where you started. They can have complex dynamics that make it difficult to train. They are more biologically authentic.
How to train loop networks efficiently is currently receiving widespread attention. Cyclic neural networks are a very natural way to simulate continuous data. They are equivalent to a deep network with one hidden layer per time segment; in addition, they use the same weight on each time segment and input on each time segment. They can remember hidden state information for a long time, but it is difficult to train them to use this potential.
3. Symmetric connection network
Symmetrically connected networks are a bit like circular networks, but the connections between cells are symmetric (they have the same weight in both directions). Symmetrically connected networks are easier to analyze than circular networks. There are more restrictions in this network because they follow the law of energy function. A symmetrically connected network without hidden cells is called a "Hopfield network." A network with symmetric connections of hidden cells is called a Boltzmann machine.
The following describes the eight neural network architectures that researchers need to be familiar with.
Sensor
When the first generation of neural networks emerged, the perceptron was only a computational model of a single neuron, which was promoted by American computer scientist Frank Rosenblatt in the early 1960s. The learning algorithm is very powerful and claims to be able to learn a lot. In 1969, Minsky and Papert published a book called Perceptrons, which analyzes what these algorithms can do and explains their limitations. Many people have scaled this limitation to all NN models. However, the perceptron learning process is still widely used for tasks with large feature vectors containing millions of features.
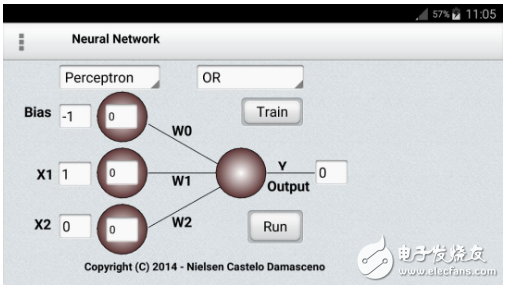
In the standard paradigm for statistical pattern recognition, we first convert the original input vector into a feature activation vector. Then, manually define the features based on your consensus. Next, we learn how to weight each feature activation to get a single scalar. If this scalar exceeds a certain threshold, we consider the input vector to be a positive sample in the target set.
The standard perceptron architecture follows the feedforward model, and the input is sent to the neuron and processed for output. In the figure below, it is represented as a bottom-up read of the network: bottom input, top output.
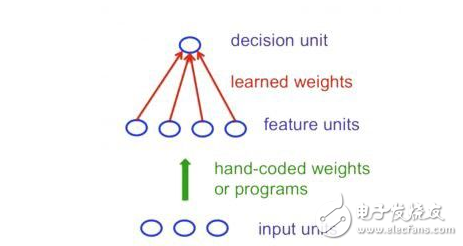
However, perceptrons do have limitations: if you use the manual feature set and use enough features, you can do almost anything. For binary input vectors, we can set a feature unit for a multi-exponential binary vector, so we can make any possible distinction between binary input vectors. However, once the characteristics of manual programming are determined, what the perceptron can learn is very limited.
This result is devastating for the perceptron because pattern recognition is to identify patterns in the case of transformations. Minsky and Papert's "group invariance theorem" believes that the learning part of the perceptron cannot learn when the transformation comes from a group. In order to identify the above situation, more feature units are needed to identify the sub-information contained in those patterns. So the skill part of pattern recognition must be solved by a manually coded feature detector instead of the learning process.
Networks without hidden cells are very limited in their input and output mappings that can be modeled. Simply adding some linear units doesn't help because the results are linear. Fixed output nonlinearity is not enough, so we need multiple layers of adaptive nonlinear hidden elements. The question is how to train such a network. We need an effective way to adapt to ownership, not just the last layer, so it's hard. Learning the weight of entering the hidden layer is equivalent to learning characteristics, which is very difficult because no one directly tells us what the hidden layer should do.
2. Convolutional neural networks
Machine learning research has been widely focused on object detection issues. There are a variety of things that make it difficult to identify objects:
Image segmentation: Real objects are always doped with other objects. It is difficult to determine which parts belong to the same object. Some parts of the object can be hidden behind other objects.
Object Illumination: The intensity of a pixel is strongly affected by illumination.
Image distortion: Objects can be deformed in a variety of non-affine ways. For example, handwriting can also have a big circle or just a pointed end.
Scenario support: The categories to which objects belong are usually defined by how they are used. For example, chairs are designed to let people sit on them, so they have a variety of physical shapes.
Perspective: The image change caused by the viewpoint change that the standard learning method cannot cope with, and the obtained information changes with the input dimension (ie, pixel).
Dimensional hopping: Imagine a medical database, a neuron that is usually used to learn weight, and is now suddenly used to learn the age of the patient! To apply machine learning, we first need to eliminate this dimension jump.

The replication feature method is currently the main method for neural network to solve the target detection problem. Use the same feature extractor in different locations. It can also be copied in size and orientation, which is tricky and expensive. Replication greatly reduces the number of free parameters to learn. It uses several different feature types, each with its own copy detector image. It also allows each image block to be represented in a variety of ways.
So how is the replication feature detector implemented?
The amount of change such as the activation value: the method of copying the feature does not make the activation value of the neuron unchanged, but the amount of change in the activation value can be made the same.
Knowledge invariant: If a feature is active at certain locations during training, the feature detector is valid at various locations during the test.
In 1998, Yann LeCun and his collaborators developed LeNet's handwritten digit recognizer. It uses backpropagation in the feedforward network. This feedforward network is more than just a recognizer. It has many hidden layers. Each layer has many mappings of duplicate units, which aggregate the output of nearby replica units. A wide net that can handle several characters at the same time, and a clever way to train a complete system. Later officially named as a convolutional neural network. An interesting fact: this network is used to read about 10% of checks in North America.
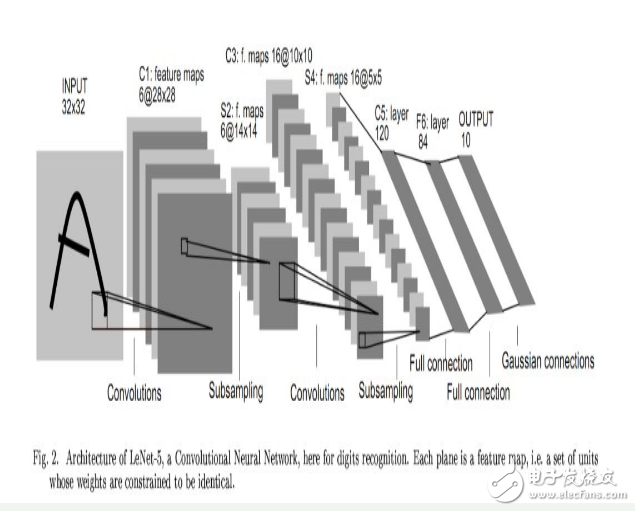
Convolutional neural networks can be used for all work related to object recognition from handwritten numbers to 3D objects. However, identifying real objects from color photos downloaded from the web is much more complicated than recognizing handwritten numbers. It is a hundred times larger than the handwritten number category (1000:10), hundreds of times the handwritten number of pixels (256 & TImes; 256 colors: 28 & TImes; 28 gray), is a two-dimensional image of the three-dimensional scene, need to segment the chaotic scene, and each The picture has multiple objects. In this case, will the same type of convolutional neural network work?
Then in ImageNet's 2012 ILSVRC competition, which is known as the Computer Vision's annual Olympic competition, the title is a dataset containing approximately 1.2 million high-resolution training images. The test image does not display the initial comment (no split or label), and the algorithm generates a label that specifies what object exists in the image. Advanced computer vision teams from institutions such as Oxford, INRIA, and XRCE have applied the best computer vision methods available to this data set. Computer vision systems are often complex multi-level systems that often need to be optimized by manual tuning at an early stage.

The winner of the competition, Alex Krizhevsky (NIPS 2012), developed the type of deep convolutional neural network pioneered by Yann LeCun. Its architecture consists of 7 hidden layers (excluding the pooling layer). The first five layers are convolutional layers and the last two layers are fully connected layers. The activation function is modified to a linear unit in each hidden layer. These trainings are faster and more expressive than the LogisTIc unit. In addition, when nearby units have stronger activities, it also uses competition normalization to suppress hidden activities, which contributes to changes in intensity.
There are some technical means to significantly improve the generalization ability of neural networks:
Randomly pick 224 × 224 block images from 256 & TImes; 256 images to get more data, and use the left and right reflection of the image. In testing, combine 10 different images: four corners plus the middle, plus five of them flipped horizontally.
Use "dropout" to adjust the weight of the global connection layer (which contains most of the parameters). Dropout refers to the random removal of half of the hidden cells in one layer of each training sample, so that it no longer relies too much on other hidden units.
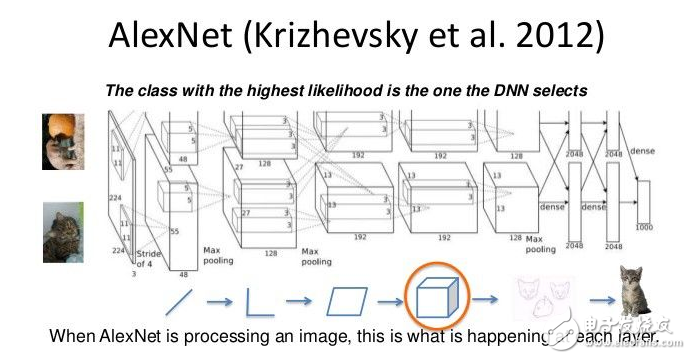
In terms of hardware requirements, Alex used a very efficient convolutional network implementation on two NVIDIA GTX 580 GPUs (more than 1000 fast small cores). The GPU is well suited for matrix multiplication and has a very high memory bandwidth. This allowed it to train the network in a week and quickly combined the results of 10 image blocks during the test. If we can exchange state fast enough, we can spread a network on many cores. As the kernel gets cheaper and the data set gets bigger and bigger, large neural networks will grow faster than older computer vision systems.
3. Recurrent neural network
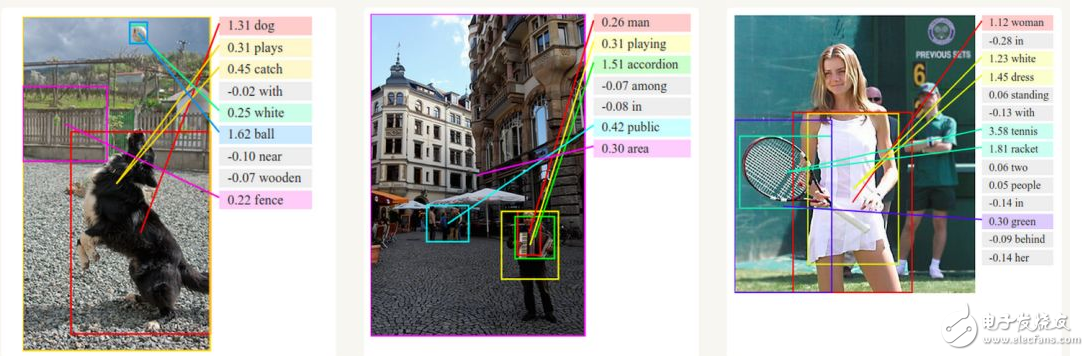
In order to understand the cyclic neural network, we need a brief overview of the sequence modeling. When machine learning is applied to sequences, we often want to convert input sequences into output sequences in different domains; for example, converting a series of sound pressures into a sequence of words. When there is no separate target sequence, we can try to predict the next item in the input sequence as the learning goal of the network. The target output sequence is the next step in the input sequence. It seems more natural than trying to predict a pixel based on other pixels of a picture or predicting a part based on the rest of the image. The next item in the prediction sequence blurs the distinction between supervised learning and unsupervised learning. It uses a method designed to supervise learning, but it does not require separate target data.
The no memory model is the standard method for this task. Specifically, the autoregressive model can predict the next item from a fixed number of previous items by using "delay taps", and the feedforward neural network is a generalized autoregressive model using one or more layers of nonlinear hidden elements. However, if we give the generated model some hidden state and make this hidden state dynamic inside, we will get a more interesting model: it can store information in a hidden state for a long time. If the dynamics of the hidden state generate noise from the hidden state, we will never know its exact hidden state. All we can do is to infer the probability distribution of the hidden state vector space. This inference only applies to 2 hidden state models.
Cyclic neural networks are very powerful because they combine two attributes: 1) distributed implicit states, which allow them to efficiently store large amounts of information about the past; 2) nonlinear dynamics that enable them to update implicit states in complex ways. . With enough neurons and time, RNN can calculate what any computer can calculate. So what kind of behavior can RNN behave? They can vibrate and stabilize at point attractors, which can be confusing. You can also execute many different applets by using different subsets of hidden states, each of which captures a piece of knowledge, and all of which can run in parallel and interact in a more complex way.
However, the computing power of RNN makes them difficult to train. Training an RNN is quite difficult due to gradient bursts and gradients disappearing. What happens to the size of the gradient when we perform multi-layer backpropagation? If the weight is small, the gradient will shrink exponentially. If the weight is large, the gradient will grow exponentially. Typical feedforward neural networks can cope with these exponential effects because they have few hidden layers. However, in training long sequences of RNNs, gradients can easily explode or disappear. Even if the initial weight selection is good, it is difficult to detect the current target output that depends on the input before multiple time steps, so the RNN is difficult to handle the long-range dependencies in the sequence.
There are basically four effective ways to learn RNN:
Long-term and short-term memory: A small module that uses RNN for long-term memory values.
Hessian Free optimization: By using a cool optimizer to handle gradient disappearance, the optimizer can detect small gradients with smaller curvatures.
Echo state network: By carefully initializing the connections between layers (input -> hidden layer, hidden layer -> hidden layer, output -> hidden layer), ensure that the hidden state has a large weakly coupled oscillating storage, which can be selectively input These oscillators are driven by ground.
Good initialization with momentum: Initialize like an echo state network, then use momentum to learn all connections.
4. Long-term and short-term memory networks
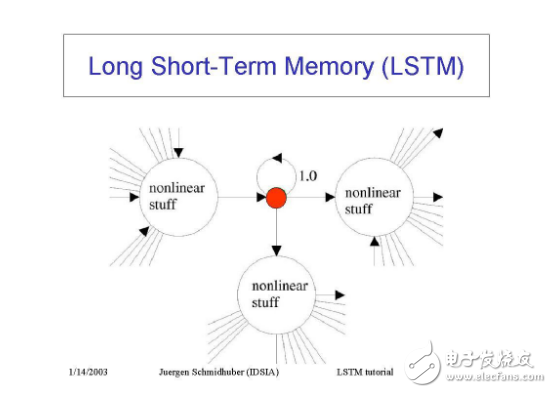
Hochreiter and Schmidhuber (1997) solved the problem of obtaining long-term memory of RNN (such as hundreds of time steps) by constructing long- and short-term memory networks. They use logic and linear units with multiplicative interactions to design memory cells. Whenever the "write" door is opened, the message will enter the unit. When the "hold" door is open, the information will remain in the unit. Information can be read from the unit by opening the "read" gate.
Handwritten cursive recognition is a task that is particularly suitable for RNN. The input is a sequence of (x, y, p) coordinates of the nib, where p is whether the pen is up or down. The output is a sequence of characters. Graves and Schmidhuber (2009) show that RNN with LSTM is the best system for cursive recognition. In short, it uses a series of small images instead of pen coordinates as input.

5. Hopfield Network
Nonlinear units of the cyclic network are often difficult to analyze. They can behave in different ways: stable to a stable state, oscillating, or following unpredictable chaotic trajectories. A Hopfield network consists of binary threshold elements with a continuous connection between them. In 1982, John Hopfield realized that if the connection is symmetrical, there is a global energy function. Each binary "structure" of the entire network has energy, and the binary threshold decision rule allows the network to get the minimum value of the energy function. A simple way to make use of this type of calculation is to use memory as the minimum energy of the neural network. The energy minimum is used to represent the memory so that the memory is addressable. You can only access part of a project to access this project. This is a great damage to the hardware.
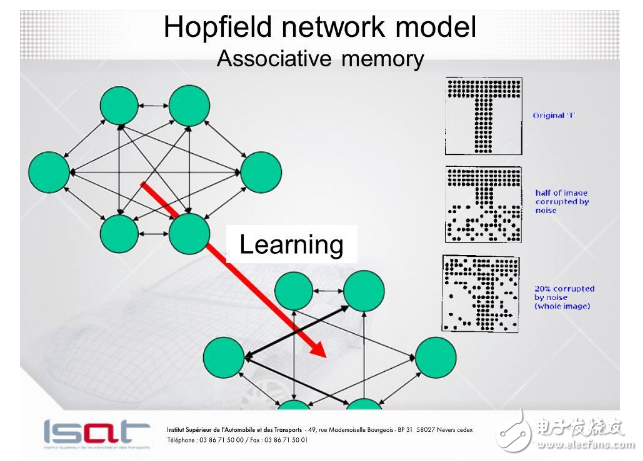
Whenever we remember a configuration, we want to create a new energy minimum. But what if there are two minimums near the middle position? This limits the capacity of the Hopfield network. So how do you increase the capacity of the Hopfield network? Physicists believe that their known mathematical knowledge can explain the workings of the brain. Many papers on the Hopfield network and its storage capacity have been published in the journal Physics. In the end, Elizabeth Gardner believes that there is a better storage rule - the "all-in-one" that gives weight. This is not a one-time storage vector, but rather a looping of the training set and using the perceptron convergence process to train each unit to have the correct state, given the state of all other elements in the vector. Statisticians call this technique "pseudo-possibility."
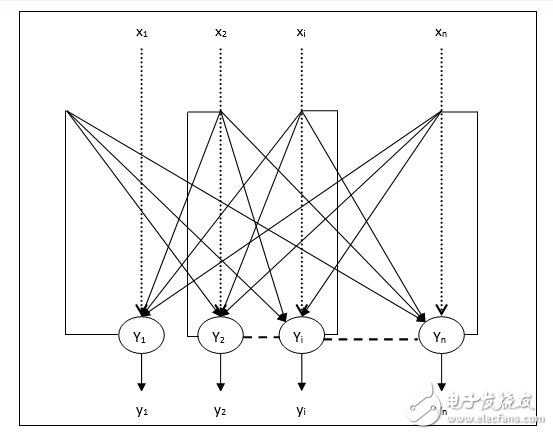
The Hopfield network has another computing feature. Instead of using the network to store memory, we use it to construct information for sensory input. The input is represented by the visible unit, the state of the hidden node is used to express the information of the input node, and the energy is used to indicate the bad information (low energy state to express a good interpretation).
6. Boltzmann Machine Network
The Boltzmann machine is a random recurrent neural network. It can be thought of as a randomly generated counterpart of the Hopfield network. It is one of the first neural networks to learn internal representations, able to represent and solve difficult combination problems.
The learning goal of the Boltzmann machine learning algorithm is to maximize the product of the probability that the Boltzmann machine is assigned to the binary vector in the training set. This is equivalent to maximizing the sum of the logarithmic probabilities that Boltzmann assigns to the training vector. That is, if we do the following, maximize the probability that we get N training cases: 1) Let the network be stably distributed at different times without external input; 2) Sampling the visible vector once.
In 2012, Salakhutdinov and Hinton proposed an efficient small batch learning program for Boltzmann machines.
For positive phase, the hidden probability is first initialized to 0.5, the data vector on the visible unit is clamped, then all hidden units are updated in parallel, and the hidden unit is updated in parallel using the mean field method until convergence. After the network converges, each connected unit pair Pi Pj is recorded and all data is averaged in the smallest batch.
For negative phase: First keep a set of "fantasy particles" (that is, a system of pairs (Si, Sj)?). Each particle has a value in the global configuration. Then serially update all the cells in each fantasy particle several times. For each connected unit, average the SiSj of all the fantasy particles.
In a normal Boltzmann machine, random updates of the unit need to be continuous. There is a special architecture that allows for more efficient alternating parallel updates (no connections within the layer, no jump layer connections). This small batch program makes the Boltzmann machine update more parallel. This is called the Deep Boltzmann Machine (DBM), a regular Boltzmann machine that lacks many connections.
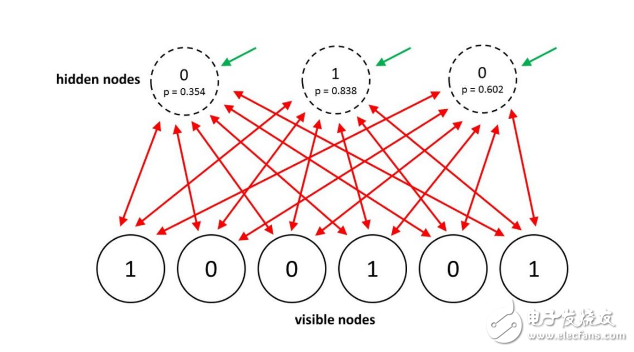
In 2014, Salakhutdinov and Hinton presented an upgraded version of their model called the Restricted Boltzmann Machine (RBM). They make reasoning and learning easier by limiting connectivity (the hidden unit has only one layer and there are no connections between hidden units). In RBM, heat balance is achieved in one step when the visible unit is clamped.
Another effective small batch RBM learning program looks like this:
For a positive phase, the data vector of the visible cell is first clamped. Then calculate all visible and hidden cell pairs
For the negative phase, also keep a set of "fantasy particles" (that is, a system of pairs (Vi, Hj)?). Then alternately update all the cells in each fantasy particle several times in parallel. For each connected unit pair, all fantasy particles ViHj are averaged.
7. Deep belief network
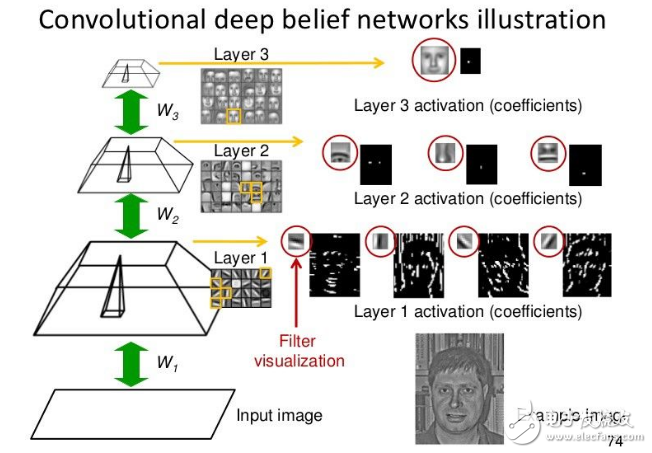
Backpropagation is considered to be the standard method in artificial neural networks for calculating the error contribution of each neuron after processing a batch of data. However, there are some important issues with using backpropagation. First, it requires tagged training data; almost all data has no tags. Second, the learning time is not ideal, which means that the network with a lot of hidden layers is very slow. Third, it may fall into a local minimum, so for deep networks, they are still far away.
To overcome the limitations of backpropagation, researchers have considered using unsupervised learning methods. This helps maintain the efficiency and simplicity of using gradient methods to adjust weights, and it can also be used to model the structure of the sensing input. In particular, they adjust the weights to maximize the probability that the generated model will produce sensory inputs. The question is what kind of build model should we learn? Can it be an energy model like the Boltzmann machine? Or is it a causal model composed of idealized neurons? Or a mix of the two?
The belief network is a directed acyclic graph composed of random variables. We can observe some variables using the belief network. We want to solve two problems: 1) reasoning problem: inferring the state of unobserved variables; 2) learning problems: adjusting the interaction between variables to make the network more likely to generate training data.
The graphical structure and conditional probabilities of early graphical models were expertly defined. At the time, these graphical connections were sparse, so the researchers initially focused on making the right inferences, not on learning. For neural networks, learning is the key, and handwriting knowledge is not cool, because knowledge comes from learning training data. The purpose of neural networks is not to be interpretable or to make reasoning easier by sparse connectivity. However, there is also a network of beliefs in the neural network version.
There are two types of generated neural networks consisting of random binary neurons: 1) based on energy using symmetric connections to connect binary random neurons to obtain Boltzmann machines; 2) we pass causal relationships in a directed acyclic graph The SBN is obtained by connecting binary random neurons. The description of these two types is beyond the scope of this article.
8. Deep automatic encoder
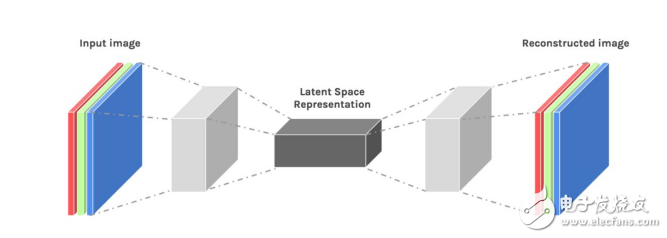
Finally, let's discuss the depth autoencoder. Deep autoencoders are a very good way to reduce dimensionality nonlinearly for the following reasons: they provide two flexible mapping methods. The learning time of the training case is linear (or better) and the final coding model is quite compact and fast. However, using backpropagation to optimize deep autoencoders is difficult. In the case where the initial weight is small, the back propagation gradient disappears. Now that we have a better way to optimize them, either use unsupervised layer-by-layer pre-training or carefully initialize the weights like an echo state network.
For pre-training tasks, there are actually three different types of shallow autoencoders:
Restricted Boltzmann machine as an automatic encoder: When we train a restricted Boltzmann machine with a one-step contrast divergence, it tries to make the reconstruction look like data. It's like an auto-encoder, but it enforces regularization by using binary activities in the hidden layer. After the maximum possible training, the restricted Boltzmann machine is not like an automatic encoder. We can replace the RBM stack for pre-training with a shallow autoencoder stack; however, if the shallow autoencoder is normalized by penalizing the squared weight, the pre-training is not valid (for subsequent discrimination).
Denoising autoencoder: Add noise to the input vector by setting its many components to 0 (for example, if the input data is lost). They still need to reconstruct these components, so they must extract features that capture the correlation between the inputs. Pre-training is very effective if we use a stack that represents an autoencoder. As good as or better than RBM pre-training. Since we can easily calculate the value of the objective function, it is easier to evaluate the pre-training. It lacks the good variational boundaries we get with RBM, but this is only a theoretical problem.
Compressed Autoencoders: Another way to normalize autoencoders is to make the activities of hidden units as insensitive as possible to the input, but they cannot ignore these inputs because they have to rebuild these inputs. We do this by penalizing the squared gradient of each hidden activity relative to the input. The compression autoencoder works well when pre-training. The code tends to make a small number of hidden units sensitive to input changes.
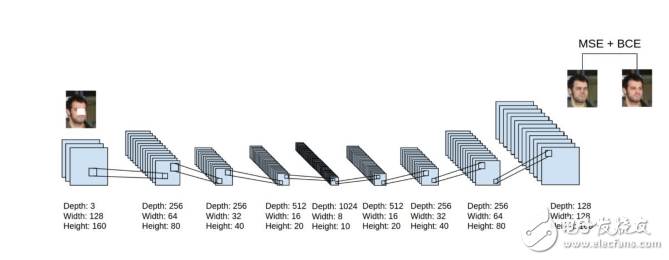
In short, there are now many different ways to perform layer-by-layer pre-training of functions. For data sets that do not have a large number of tagged cases, pre-training facilitates subsequent discriminative learning. For very large tagged data sets, it is not necessary to use unsupervised pre-training to initialize the weights used in supervised learning, even for deep networks. Pre-training is the first good way to initialize deep network weights, but there are other ways. However, if we make the network very large, we will be inseparable from pre-training!
Final welfare
Neural networks are one of the most beautiful programming paradigms of all time. In traditional programming methods, we tell the computer what to do, breaking down the big problem into many precisely defined small tasks that the computer can easily perform. In contrast, in a neural network, we don't need to tell the computer how to solve our problem, but let it learn by observing the data to find a solution to the problem at hand.
Today, deep neural networks and deep learning excel in many important issues such as computer vision, speech recognition, and natural language processing. They are being deployed on a large scale by companies such as Google, Microsoft and Facebook.
I hope this article will help you learn the core concepts of neural networks, including modern techniques for deep learning.
Antenk battery holders are manufactured from UL rated 94V-O materials. Contacts made of high quality spring steel to assure reliable connections and allow contact resistance. Each contact is clearly marked with its polarity to assure proper battery insertion.
Lightweight and rugged, these PCB coin cell holders offer uniquely designed notched battery slot that assures quick and easy insertion and replacement of all major battery manufacturers' lithium coin cells.
Coin Cell Battery Holders

We have created a wide variety of coin cell battery holders for use in all types of devices, and from handheld medical devices to server motherboards we have solutions for any application. The ever increasing types, sizes, and sheer number of devices which use coin cell battery holders have been keeping us busy, and we have a similarly increasing selection of coin cell battery holder designs. After all, the perfect coin cell battery holder for a handheld medical device is going to be vastly different from the one for a server motherboard.
Lithium Coin/button Cell-Holders Battery Holders
Compact and vertical holders allow battery insertion and replacement from the top, making them ideal for high-density packaging
compact and vertical holders allow battery insertion and replacement from the top, making them ideal for high-density packaging, which maximizes board placement choices. The through-hole mount (THM) versions feature an "air-flow" support-leg design that facilitates soldering and quick battery insertion. The surface-mount (SMT) versions feature a "flow-hole" solder tail design for increased solder joint strength and are available on tape-and-reel.
These holders are manufactured from UL rated 94 V-0 materials. Contacts are made of high-quality spring steel to assure reliable connections and allow contact resistance. Each contact is clearly marked with its polarity to assure proper battery insertion.
Lightweight and rugged, these PCB coin cell holders offer a uniquely designed notched battery slot that assures quick and easy insertion and replacement of all major battery manufacturers' lithium coin cells.
Features and Benefits of Coin/button Cell-Holders Battery Holders
Low profile for high-density packaging
Reliable spring-tension contacts assure low-contact resistance
Retains battery securely to withstand shock and vibration
Rugged construction, light weight
Unique notched battery slot assures quick and easy battery insertion and replacement
Compatible with vacuum and mechanical pick and place systems
Base material UL rated 94 V-0. Impervious to most industrial solvents
THM "air-flow" design pattern enhances air circulation around battery
SMT "flow-hole" solder tail design for increased solder joint strength
Clearly marked polarities to help guard against improper insertion
Unique Coin Cell Battery Holders
Antenk has pioneered a large number of new styles of coin cell battery holders to suit the various needs of the electronics industry. Our Verticals are an excellent way to save space on a crowded board, while our Minis can save almost 3 mm in height above the PCB over traditional coin cell battery holders. Gliders are an excellent upgrade over coin cell retainers, offering more reliable connections while also having simple, tool-less battery replacements. Our newest technology is Snap Dragon, which adds a snapping cover to the traditional style of coin cell battery holders for increased reliability.
Coin Cell Battery Holders by Size of Cell
191 | 335 | A76 | CR1025 | CR1216 | CR1220 | CR1225 | CR1620 | CR1632 | CR2016 | CR2025 | CR2032 | CR2320 | CR2325 | CR2330 | CR2335 | CR2354 | CR2420 | CR2430 | CR2450 | CR2477 | CR3032 | Coin Cell | F3 iButton | F5 iButton | LR1120 | LR44 | ML414 | SR512SW | SR60 | V80H or CP1654 | iButton | BR1025 | BR1216 | BR1220 | BR1225 | BR1620 | BR1632 | BR2016 | BR2025 | BR2032 | BR2320 | BR2325 | BR2330 | BR2335 | BR2420 | BR2430 | BR2450 | BR2477 | BR3032 | Other Sizes
Coin/button Cell-Holders,Coin Cell Holder,Button Cell Holders,Lithium Button Cell Battery Holder,Lithium Coin Cell Battery Holder
ShenZhen Antenk Electronics Co,Ltd , https://www.antenk.com