RFID is a non-contact automatic identification technology that emerged in the 1990s. Its wireless communication method and the requirement of non-visual reading and writing have brought us great convenience and many security and privacy issues. Aiming at the security and privacy of RFID, many researches on enhancing RFID security privacy protection have been carried out at home and abroad, and a series of methods, such as hash lock, random hash lock and hash chain, have been proposed, but these methods are not safe or efficient. Low defects. In view of the shortcomings of the existing methods, this paper further studies the security and privacy protection of RFID.
This article refers to the address: http://
1 RFID technology and its security privacy analysis
The RFID system consists mainly of readers, tags, and back-end databases, as shown in Figure 1.
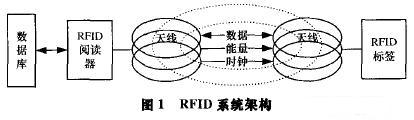
At present, RFID technology has attracted more and more attention from industry and academia, and has been widely used in various situations such as supply chain management, access control, and electronic wallet [1]. However, RFID technology is a non-contact automatic identification technology, and its security privacy threats mainly include:
(1) Illegal reading. Commercial competitors can quickly read supermarket product label data through unauthorized readers to obtain important business information;
(2) Location tracking. Through RFID tag scanning, the location of the consumer can be tracked and positioned according to the specific output of the tag;
(3) Eavesdropping. Signal transmission distance of the RFID system in the forward channel
Farther away, the eavesdropper can easily steal the signal data from the reader;
(4) Refusal of service. The artificial signal interference makes the legal reader unable to read the tag data normally;
(5) Pretending to swindle. By masquerading as a legitimate tag, the reader is provided with erroneous data;
(6) Replay. According to the data communication that the eavesdropped reader and tag ask, the previous communication behavior is repeated to obtain the data information.
2 RFID security privacy protection
The security and privacy of RFID has hindered the further promotion of RFID technology, which has aroused the attention of consumers and strengthened the security and privacy protection of RFID.
2.1 Prerequisites and requirements
It is assumed that the communication between the reader and the back-end database is performed on a secure and reliable connected channel, but the wireless communication between the reader and the tag is easily eavesdropped. To popularize RFID technology, it is necessary to ensure the low cost implementation of RFID tags.
Because the standard security mechanism requires more complicated calculations, such as SHA-1 requires about 12K gates, which cannot be realized on low-cost tags, so low-cost one-way hash function can be used for encryption [2].
A secure RFID system should be able to withstand various attacks, and in view of the worse situation, even if an outsider obtains secret data inside the tag, it should ensure that it cannot track the historical activity information related to the tag, that is, guarantee forward security. .
2,2 typical method
Typical access control methods for enhancing RFID security privacy protection include Hash locks, random hash locks, and hash chains, all based on one-way hash functions.
2.2.1 Hash Lock (Hash Lock) [2]
The Hash lock method is used to control the read access of the tag. The working mechanism is as follows:
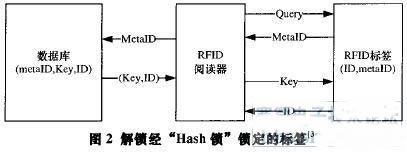
Locking the tag: For a tag with a unique ID, the reader randomly generates the Key of the tag, calculates metaID=Hash(Key), and sends the metaID to the tag; the tag stores the metaID and enters the locked state. The reader stores (metaID, Key, ID) in the backend database and indexes it with a metaID.
Unlock the tag: When the reader asks for the tag, the tag answers the metaID; the reader queries the background database, finds the corresponding (metaID, Key, ID) record, and then sends the key value to the tag; after the tag receives the Key value, it calculates the hash ( Key) value, and compared with the metaID value stored by itself, if Hash(Key)=metaID, the tag sends its ID to the reader, then the tag enters the unlocked state and opens all functions for the nearby reader, such as Figure 2 shows.
Advantages of the method: It is difficult to decrypt the one-way hash function, so the method can prevent the unauthorized reader from reading the tag information data, and to some extent provide privacy protection for the tag; the method only needs to implement a hash on the tag. The calculation of functions, as well as the addition of stored metaID values, is therefore easy to implement on low cost tags.
Defects of the method: Since the data replied by the tag is specific each time it is queried, it cannot prevent the location tracking attack; the data transmitted by the reader and the tag is not encrypted, and the eavesdropper can easily obtain the tag Key and ID values.
2.2.2 Random Hash Lock (Random Hash Lock)
In order to solve the problem of location tracking in Hash lock, the Hash lock method is improved, and a random hash lock method is adopted. First introduce the string connection symbol ", such as the connection between the tag ID and the random number R is expressed as "IDIIR". In this method, the database stores the ID value of each tag, set to IDl, ID2.
In this method, each time the tag is answered is random, it is possible to prevent a position tracking attack based on a specific output. However, this method also has certain drawbacks: (1) The reader needs to search all tag IDs and calculate Hash (IDkIIR) for each tag. Therefore, when the number of tags is large, the system delay will be long and the efficiency is not high; 2) Random Hash lock does not have forward security. If the enemy obtains the tag ID value, the Hash (IDIIR) value can be calculated according to the R value, so the tag historical position information can be traced.
2.2.3 Hash Chain [4]
NTT Lab proposes a hash chain method, which guarantees forward security. The working mechanism is as follows: Locking the tag: For the tag ID, the reader randomly selects a number S1 to send to the tag, and stores (ID, S) to the background. Tag storage in the database
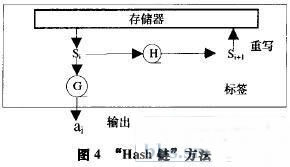
After going to Sl, it enters the locked state.
Unlocking the tag: In the i-th transaction exchange, the reader sends an inquiry message to the tag, the tag answers ai=G(S.), and updates Si+l=H(s.), where G and H are one-way hash functions. ,As shown in Figure 4.
After the reader receives ai, it searches all the (ID, S1) data pairs in the database and calculates for each tag.
Ai = G(H (s1)), compare whether ai* is equal to ai, and if they are equal, return the corresponding ID.
Method advantage: It is indistinguishable, because G is a one-way hash function, and outsiders get a. The value cannot be derived from S. Value, when an outsider observes the label output, G outputs a random number, so you cannot set a. And a. +l is linked; it has forward security. Because H is a one-way hash function, even if the Si+1 value is stolen, the S value cannot be derived, so the tag history activity information cannot be obtained.
Method disadvantage: It is necessary to calculate ai*:G(H(s1)) for each label. If the number of labels stored in the database is N, then N records search, 2N hash functions, N comparisons, calculations are required. The comparison amount is large, and it is not suitable for the case where the number of tags is large.
3 Key value update random hash lock
In view of the shortcomings of the above several security privacy protection methods, combined with the ideas of several methods, this paper proposes a "Key value update random Hash lock" method to achieve safe and efficient read access control.
3.1 Working principle
The database record mainly includes 4 columns: H (Key), ID, Key, Pointer, and the primary key is H (Key). The ID is the unique identifier of the label, Key is the random keyword selected by the reader for each label, H(Key) is the one-way Hash function H of Key, and Pointer is the data record association pointer, which is mainly used to guarantee data. Consistency [5].
The basic working principle of the method is explained in detail below:
(1) Lock the label
For the tag ID, the reader first randomly selects a number as the key of the tag, sends the Key value to the tag, and establishes the initial record (H(Key), ID, Key, 0)) of the tag in the database, and the tag will After the received Key value is stored, it enters the locked state.
(2) Unlock the label
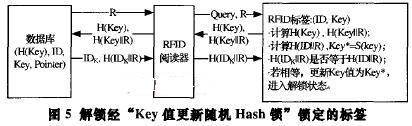
1) The database first generates a random number R, which is transmitted to the reader, and then the reader sends the query messages Query and R to the tag;
2) The tag calculates the values ​​of H(Key) and H(KeylIR) according to the received R and its own Key values, and then sends the (H(Key), H(KeylIR)) data pair to the reader, and then calculates H by itself. (IDIIR) and Key = S(key), but the Key value is not updated at this time.
3) The reader looks up the records in the database, if the record i is found:
(H(Keyi), IDk, Key., Pointeri), where H(Key.):H(Key), then the database calculates H(KeyjIIR) and compares H(Key ItR) with the received H(KeyIIR) value Is it equal? If they are not equal, the message is ignored, indicating that the tag is an illegal tag, and the reader completes the validity verification of the tag; if they are equal, the next step is continued;
4) The database calculates the value of H(IDkIIR) and transmits the values ​​of IDk and H(IDkIIR) to the reader. The reader then sends H (IDkIIR) to the tag;
5) The database calculates the values ​​of Key*i=S(key.) and H(Key*). If Pointeri:O, add a new record J:(H(Key*i), IDbKey i,i) in the database, and modify the record i to (H(Key.), IDbKeyij); if Pointer !=O , then find the first Pointer. Record, modify it to (H(Key i), IDk, Key i, i);
6) After the tag receives H(IDkIIR), compare whether it is equal to the H(IDIIR) calculated by the tag in step 2. If it is equal, update its own Key value to Key, and the tag enters the unlocked state. The device opens all its functions; if it is not equal, it indicates that the reader is an illegal reader, the tag remains silent, and the tag completes the verification of the reader. As shown in Figure 5.
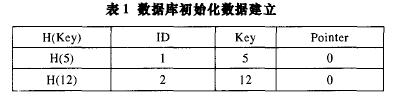
3.2 Numerical experiments
Let the database initially store two tags, the ID is 1, 2, and the randomly selected Keys are 5 and 12 respectively. The database initialization is shown in Table 1.
.
Let the reader ask the tag with ID 1 first. The reader first sends an inquiry message to the tag and a random number 3. The tag answers the data to the reader (H(5), H(5II3)), and then calculates its own H (IDIIR). ) = H (1Il3) value and Key = s (5); the reader looks up the backend database according to H(5), finds the record 1: (H(5), 1, 5, 0), and the database calculates H(KeyllR) = H(5lI3), which is equal to the received H(5113), and it is verified that the label is legal; then the database calculates H(IDIIR)=H(1 113) and transmits (1,H(1113)) to the reading. The reader knows that the ID of the tag is 1, and then the reader sends H(1113) to the tag; the database calculates Key*I=s(5), and because of PointerI=0, a new record is created in the database: (H(s(5)), 1, s(5), 1), and change record 1 to (H(5), 1, 5, 3). After the tag receives the data H (1 113), the comparison finds that it is equal to the previously calculated H (IDIIR), and then updates its own Key value to s(5). The data records in the database at this time are shown in Table 2.

The next time you communicate with Tag 1, the database finds the third record according to the tag's H(Key)=H(s(5)). If the Pointer of the record is 1, the record of the second update of the Key value will be Cover the first record.
After the tag has been queried once, the database has always maintained two data records related to the tag, mainly
It is to ensure the consistency of the data. Assuming that the data H(ll3) sent by the reader in this communication is not successfully received by the tag, the Key value of the tag 1 will not be updated, and the third record of the database is wrong. Then, in the next communication with the tag 1, the record 1 is still found, and the database has the Pointer value of 3 according to the record 1, and the third record is modified, thus ensuring the consistency of the data.
3.3 Performance Analysis and Method Features
(1) Simple and practical. Complex calculations such as random number generators are moved to the back-end database to reduce the complexity of the tag. The tag only needs to implement two Hash functions H and s, which is easy to implement on low-cost tags.
(2) Forward security. Because the Key value of the tag is updated by the one-way hash function s after each transaction exchange, even if the outsider obtains the current tag Key* value, the external key cannot be derived, so the historical activity information related to the tag cannot be obtained.
(3) The machine has a small computational load and high efficiency. In each inquiry process, it is assumed that the number of tags stored in the database is N. In this method, the background database needs to perform 2N record searches (because there are two records for each tag), and three Hash functions H (KeylIR) are performed. S (Key), H (IDIIR) calculation and 1 time value comparison, and generate 1 random number R. Compared with the Hash chain method, it is necessary to calculate 2N hash functions, N record searches, and N value comparisons. Because the Hash function has a long calculation delay and large resource consumption, when N is large, the load of the method system will be It is much smaller, faster, shorter, and more efficient, but more secure.
(4) Adapt to the situation with a large number of labels. As the number of tags increases, the time required for computer search and calculation increases slowly, and can accommodate a large number of tags.
(5) Two-way verification of identity is achieved. Through the calculation and comparison of Hash (KeyllR), the reader implements the verification of the tag; through the calculation and comparison of Hash (IDIIR), the tag realizes the verification of the reader.
(6) Effectively implement security and privacy protection.
1) Anti-illegal reading: Only the legally authenticated reader can read the tag data information;
2) Anti-position tracking: Since the random number R and the key value of the tag are updated and changed, the data (H(Key), H(KeylIR)) value of each answer is also different, which can prevent an outsider from performing according to a specific output. Tracking and positioning; 3) Anti-eavesdropping: The transmitted ID value and Key are encrypted by Hash function, and it is difficult for outsiders to decrypt the ID and Key values, thus effectively preventing eavesdropping;
4) Anti-spoofing spoofing: Since the outsider cannot know the Key value, it can not simulate the legal tag transmission (H (Key), H (KeylIR)) data, thus effectively preventing the camouflage spoofing attack;
5) Anti-replay: The R value generated each time is random. Even if the outsider taps the H (ID IIR) data sent by the legitimate reader, the H (ID IIR) value cannot be simulated again, effectively preventing it. Replay attack.
4 Conclusion
The "Key value update random hash lock" method has the characteristics of low cost, small load, high efficiency, good security, etc., and can ensure forward security, basically making up for the defects of the current security protection method such as insufficient security and low efficiency. It is a more practical algorithm. However, there are still some shortcomings in this method. For example, the tracking tracking performed by the enemy according to the traffic analysis (calculating the number of tags) cannot be prevented, and the security improvement also increases the calculation delay of the tag part, which needs further research and improvement.
LED wash wall lamp, as the name implies, let the light like water wash the wall, mainly used for building decoration lighting, and also used to outline the large buildings.Since LED has the characteristics of energy saving, high luminous efficiency, rich color and long life, the washing wall lamp of other light sources is gradually replaced by LED washing wall lamp in 2013.

Product size

Technical parameters
1. Main material:High - pressure cast aluminum, high - light ultra - white tempered glass, back flame retardant ABS;
2. Surface treatment:UV Polyester powder coating;
3. The light body color:Dark grey;
4. Safeguard procedures:Silica gel ring compacted waterproof;
5. Average lifetime:350mA20000hours,500mA15000hours;
6. Control mode:CC/DMX512;
7. Operating ambient temperature:-25℃~50℃
8. The light colored temperature: Red/Green/Yellow/Amber/Vermilion/Acid blue/3000K/4000K/5000K/6000K
9. Light distribution device:Optical lens series:8°/15°/25°/45°/10×30°/10×60°/20×40°
10. Working voltage:DC24V
11. Way to install:Single U/Double U Adjustable Angle bracket
12. Level of protection:IP65
13. Working environment humidity:10%~90%
Led Wall Washer Lamp,Led Wall Washer Light Fixtures,Led Wall Washer Flood Light ,Led Wall Washer Light Products
Jiangsu chengxu Electric Group Co., Ltd , http://www.chengxulighting.com