Professor Yann Lecun, one of the three great cows of deep learning, gave an interesting metaphor about supervised learning, unsupervised learning and reinforcement learning in machine learning. He said: If you compare intelligence to a cake, Then unsupervised learning is the cake body, and the enhanced learning is the cherry on the cake, so supervised learning can only be counted as the frosting on the cake (Figure 1).

Figure 1 Yann LeCun's image metaphor for supervising learning, enhancing the value of learning and unsupervised learning
Advances in depth of supervised learning in the field of computer vision
Image Classification (Image ClassificaTIon)
Since Alex and his mentor, Hinton (the originator of deep learning), in the 2012 ImageNet Large-Scale Image Recognition Competition (ILSVRC2012), the second place was scored with a score of 10% higher than the second place (83.6% of Top5 accuracy) (74.2 After the use of traditional computer vision methods, deep learning really began to heat up, and the Convolutional Neural Network (CNN) became a household name, from 12 years of AlexNet (83.6%) to the 2013 ImageNet large-scale image recognition competition. 88.8%, then 92.7% of VGG in 2014 and 93.3% of GoogLeNet in the same year. Finally, by 2015, in the image recognition of 1000 categories, Microsoft proposed ResNet with 96.43% of Top5 correct rate. , reaching more than human level (human correct rate is only 94.9%).
Top5 precision means that given a picture, the model gives the 5 most probable labels, as long as the correct label is included in the predicted 5 results.
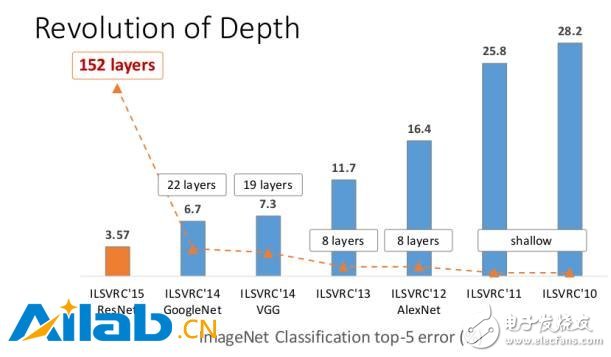
Figure 2 Evolution trend of image recognition error rate in ILSVRC competition from 2010 to 2015
Image Detection (Image DecTIon)
Along with the image classification task, there is another more challenging task – image detection, which refers to the object being circled with a rectangular frame while classifying the image. From 14 to 16 years, R-CNN, Fast R-CNN, Faster R-CNN, YOLO, SSD and other well-known frameworks have emerged. The average accuracy (mAP) is detected on a well-known data set of computer vision on PASCAL VOC. The average accuracy of detection (mAP) is also from 53.3% for R-CNN to 68.4% for Fast RCNN to 75.9% for Faster R-CNN. The latest experiments show that Faster RCNN combines with residual network (Resnet-101). Its detection accuracy can reach 83.8%. Deep learning detection speed is also getting faster and faster. From the original RCNN model, it takes more than 2 seconds to process a picture, 198 ms/sheet to Faster RCNN, and 155 frames/second to YOLO (the defect is lower precision). , only 52.7%), and finally the SSD with high accuracy and speed, the accuracy is 75.1%, and the speed is 23 frames/second.

Figure 3 image detection example
Image segmentation (SemanTIc SegmentaTIon)
Image segmentation is also an interesting field of research. Its purpose is to divide different objects in the image into different colors, as shown in the following figure, the average accuracy (mIoU, that is, the intersection of the prediction region and the actual region divided by the prediction region). And the actual area of ​​the union), also from the initial FCN model (image semantic segmentation full connection network, the paper obtained the best paper of CVPR2015), to 72.7% of the DeepLab framework, and then 74.7% of Oxford University's CRF as RNN. This area is an area that is still evolving and there is still much room for improvement.

Figure 4 Example of image segmentation
Image annotation – Image Captioning
Image annotation is a compelling field of research. Its purpose is to give a picture. You give me a text to describe it. As shown in the figure, the first picture in the picture is automatically given by the program. The description is “A person riding a motorcycle on a dusty dirt road†and the second picture is “Two dogs playing on the grassâ€. Due to the huge commercial value of the research (such as image search), in recent years, Baidu in the industry, Google and Microsoft, as well as the academic community to increase Berkeley, deep learning research and the University of Toronto are doing the corresponding research.

Figure 5 image annotation, generate description text based on the image
Image Generation - Text to Image (Image Generator)
The image annotation task was originally a semi-circle. Since we can generate descriptive text from the image, we can also generate images from the text. As shown in Figure 6, the first column "A large passenger plane flies in the blue sky", the model automatically generates 16 pictures according to the text, the third column is more interesting, "a group of elephants walking on dry grass" (this is a bit contrary to common sense, Because elephants are generally in the rain forest and do not walk on dry grass, the model also generates corresponding pictures accordingly, although the quality of the generated is not too good, but it has also been quite satisfactory.

Figure 6 generates a picture based on the text
Reinforcement Learning
In the supervised learning task, we give a fixed label to a given sample, and then train the model. However, in the real environment, it is difficult to give the labels of all the samples. At this time, the reinforcement learning is usually used. In other words, we give some rewards or punishments. Intensive learning is to let the model try and try it out. The model can optimize itself to get more scores. The AlphaGo of the 2016 fire has used intensive learning to train, and it has mastered the optimal strategy in constant self-test and error. Using intensive learning to play flyppy bird, has been able to play tens of thousands of points.

Figure 7 reinforcement learning to play flappy bird
Google DeepMind publishes enhanced learning to play Atari games. One of the classic games is breakout. The model proposed by DeepMind uses only pixels as input, without any other prior knowledge. In other words, the model does not know. What is the ball, what it is playing, and surprisingly, after 240 minutes of training, it does not optically pick up the ball correctly, hit the bricks, it even learns to continue to hit the same position, the game The faster you win (the higher the reward).
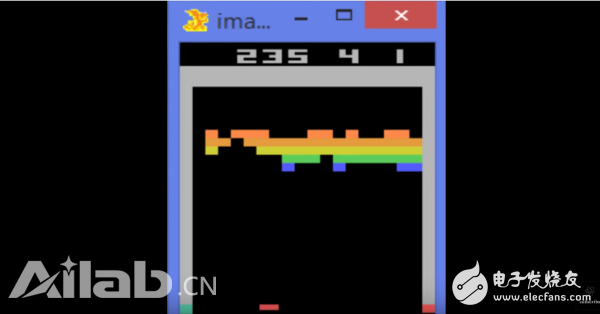
Figure 8 Using Deep Enhancement Learning to Play Atari Breakout
Reinforcement learning has great application value in the field of robotics and autonomous driving. At present, arxiv basically has corresponding papers every few days. Robots learn to try and correct to learn the best performance, which may be the best way to evolve artificial intelligence, and it is estimated to be the only way to strong artificial intelligence.
Here is a review of a review paper by Ian GoodFellow in the beginning of 2017 combined with his speech at NIPS2016 - NIPS 2016 Tutorial: Generative Adversarial Networks
Deep Unsupervised Learning – predictive learning
There are endless unlabeled data in nature compared to limited supervised learning data. Imagine if artificial intelligence can automatically learn from the vast natural world, isn't it a new era? At present, the most promising areas of research may be unsupervised learning, which is why Professor Yann Lecun compared unsupervised learning to artificial intelligence big cakes.
After deep learning Ian Goodfellow proposed to generate a confrontation network in 2014, the field is getting hotter and hotter, becoming one of the hottest areas in 16 years of research. Daniel Yann LeCun once said: "The confrontation network is the most exciting thing since the invention of sliced ​​bread." The phrase "Da Niu" is enough to show how important it is to generate a confrontation network.
A simple explanation for generating a confrontation network is as follows: Suppose there are two models, one is the Generative Model (hereinafter abbreviated as G), the other is the Discriminative Model (hereinafter abbreviated as D), and the task of discriminating the model (D) Is to judge whether an instance is real or generated by the model, the task of generating the model (G) is to generate an instance to fool the discriminant model (D), the two models compete against each other, and the development will reach a balance, generating model generation The example is not different from the real one, and the discriminant model cannot distinguish between natural and model-generated. Taking a counterfeit businessman as an example, a counterfeit businessman (generating model) produces a fake Picasso painting to deceive the expert (discriminating model D). The counterfeit merchant has always improved his high imitation level to distinguish the expert, and the expert has been learning the true and false Picasso painting. In order to improve their ability to recognize, the two have been playing games. Finally, the Picasso paintings of the counterfeit merchants have reached the level of realism, and it is difficult for experts to distinguish between genuine and fake products. The following picture shows some of the generated images of Goodfellow in the publication of the generated confrontation network paper. It can be seen that the model generated by the model is still quite different from the real one, but this is a 14-year paper. In 16 years, this field has progressed very fast. There are Conditional Generative Adversarial Nets and InfoGAN, Deep Convolutional Generative Adversal Network (DCGAN), and more importantly, the current generation of confrontation networks has extended the reach. In the field of video prediction, it is well known that human beings mainly rely on video sequences to understand nature. Pictures only occupy a very small part. When artificial intelligence learns to understand video, it also really begins to show its power.

Figure 9 generates some images generated against the network, and the last column is the production image closest to the image in the training set.
Conditional Generative Adversarial Nets (CGAN)
The generation of the confrontation network is generally based on random noise to generate an instance of a specific type of image, and the conditional generation confrontation network is based on a certain input to limit the output, for example, according to several descriptive nouns to generate a specific instance, which is somewhat similar to the introduction of Section 1.5. The image is generated from text. The image below is a picture from the Conditioanal Generative Adversarial Nets paper, which generates a picture based on a specific noun description. (Note: the description text of the left column of the picture does not exist in the training set, that is, the picture generated by the model based on the description that has not been seen, and the description of the right column of the picture is in the training set)

Figure 10 generates a picture based on the text
Another interesting paper on conditional generation against the network is image-to-image translation. The model proposed in this paper can input the image according to one input, and then give the image generated by the model. The following figure is a picture in the paper, in which the upper left The first pair of angles is very interesting. The result of the model input image segmentation gives the result of the generated real scene, which is similar to the reverse engineering of image segmentation.
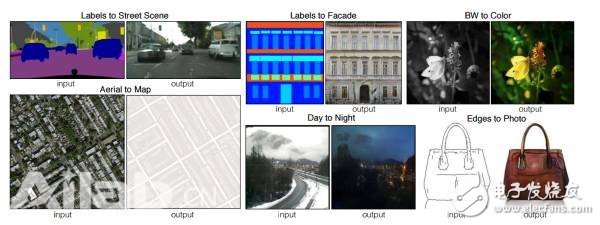
Figure 11 generates some interesting output images based on specific inputs
The generated confrontation network is also used in image super-resolution. In 2016, the SRGAN model was proposed. After sampling the original HD image, it tried to generate a more natural and closer to the original image by generating a confrontation network model to restore the image. image. In the figure below, the far right is the original image. The image obtained by sub-sampling with Bicubic Interpolation is fuzzy. The version of the residual network (SRResNet) has been cleaned a lot. We can see the image generated by SRGAN. More realistic.

Figure 12 shows an example of super-resolution against the network, the rightmost image is the original image.
Another influential paper for generating confrontational networks is the deep convolution generation against the network DCGAN. The author combines the convolutional neural network with the generated confrontation network. The author points out that the framework can well learn the characteristics of things. Very interesting results are given in the generation and image manipulation, such as Figure 13, a man with eyes - a man without glasses + a woman without eyes = a woman with eyes, the model gives a similar vectorization of the picture .

Figure 13 Example of the DCGAN paper
The development of the anti-network is very hot, and an article is difficult to list completely. Interested friends can research their own online research papers.
One of openAI's descriptions of generating blogs against the web is great because Ian Goodfellow works at OpenAI, so the quality of this blog is quite secure.
Video prediction
This direction is the author's own most interesting direction. Yann LeCun also proposed, “Replacing unsupervised learning with predictive learning.†Predictive learning works by observing and understanding how the world works, and then predicting changes in the world. Learn to perceive changes in the world and then infer the state of the world.
At this year's NIPS, MIT scholar Vondrick and others published a paper called Generating Videos with Scene Dynamics, which proposed a static image based on a static image that automatically guesses the next scene, such as giving a person Standing on the picture of the beach, the model automatically gives a small video of the next wave of waves. The model is trained on a large number of videos in an unsupervised manner. This model shows that it can automatically learn useful features in video. The following picture is the picture given on the author's official homepage. It is a dynamic picture. If it cannot be viewed normally, please go to the official website video generation example. The video in the picture below is automatically generated by the model. We can see that the picture is not perfect. But it has been quite good to represent a scene.
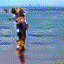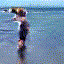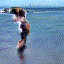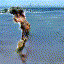

Figure 14 Randomly generated video, the waves on the beach, the scene of the train running
Conditional video generation, the following figure is to enter a static picture, the model automatically pushes a small video.


Figure 15. According to a static map of the grass, the model automatically speculates on the moving scene of the person.


Figure 16. Give a road map that automatically predicts how the train will run.
MIT's CSAIL lab also released a blog titled "Church Machines to Predict the Future," which is trained on youtube videos and TV shows (such as The Office and Desperate Housewives). If you train, The model is a picture before the kiss, the model can automatically guess the action of adding a kiss to kiss, the specific example is shown below.

Figure 17 shows a static graph, the model automatically guesses the next action
Hart's Lotter et al. proposed PredNet, which is also trained on the KITTI dataset, and then the model can predict the next few frames of the driving recorder based on the previous video. The model uses long-term and short-term memory neural networks ( LSTM) training obtained. The specific example is shown in the figure below. The pictures of the first few pictures of the driving recorder are given, and the next five frames are automatically predicted. After the model inputs several frames of images, the next five frames are predicted. As can be seen from the figure, the model prediction is made. The more ambiguous, the model has been able to give predictions of participation value.
floor standing digital signage
interactive touch table for advertising display,interactive touch table for games,interactive Touch Screen for meeting room and classroom;Digital Signage company,Digital Signage For Churches,digital signage free software,digital signage lg,digital signage with tv,The Flat Panel Displays LCD advertising message information Activpanel release system is prepared by the company`s store owners in advance. Digital Signage Media Player digital signage for chromecast,digital signage for schools,digital signage media player,The Digital Signage Displays audience does not need to increase personal investment and consumption costs, but only needs to "focus on" resources. Flat Panel Displays media player for digital signage This is easy to accept for everyone. At this point, the popularization of advertising words on LCD screens is a kind of work that is profitable and has the characteristics of Interactive Flat Panel social development and Digital Signage Displays public welfare.
digital signage displays,digital signage indoors,digital signage solutions
Jumei Video(Shenzhen)Co.,Ltd , https://www.jmsxdisplay.com